•
Featured Posts
curated
Best SEO Tool: Your Strategic Choice for Business Growth
Choosing the best SEO tool for your business isn't merely a functional decision; it's a pivotal strategic move that can empower your team, u
Read article
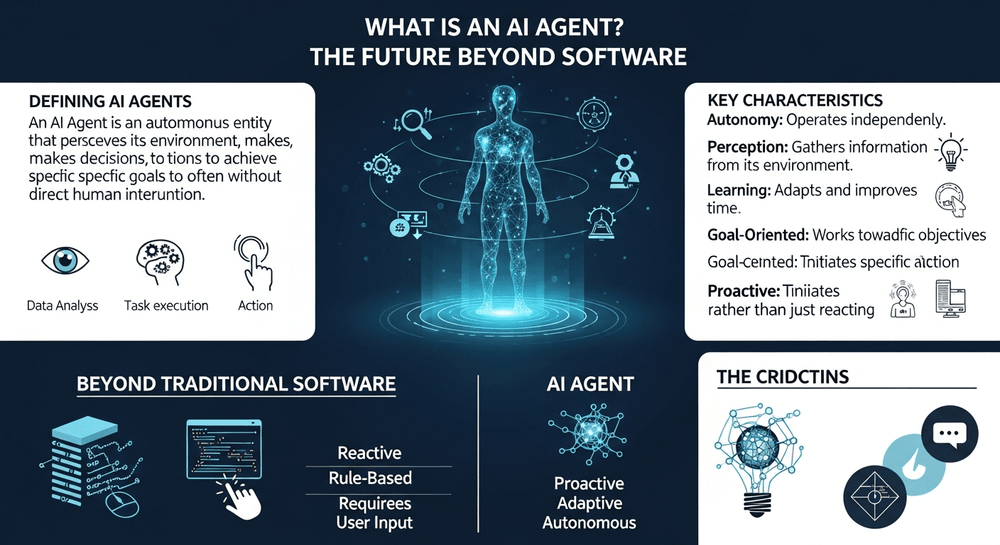
What is AI Agent? The Future Beyond Software
Wondering what is an AI agent? Discover how these autonomous systems go beyond apps to strategize and execute complex tasks. Your guide to t
Read article

What is SEO? Beginner's Roadmap for 2025 Success
If you're just starting out, the question "what is SEO" can feel like staring at a complex map. Fear not! This beginner's roadmap is your co
Read article

AI SEO: Capture User Intent Beyond Keywords
Tired of your content disappearing into the digital abyss, despite your best keyword efforts? The search engine optimization landscape is un
Read article